Enterprise GenAI (generative AI) deployments succeed when teams run them with the same discipline they apply to other user-facing services. The model sits in the middle of a pipeline that handles identity, policy, retrieval, inference, and logging. Each stage affects quality, latency, cost, and risk. A pilot can hide these dependencies. Production traffic exposes them.
Familiar sequences are seen across large organizations. A small group proves a use case in days. Leadership asks for broad rollout. Usage climbs and the system behaves differently. Response times vary across the day. The assistant answers confidently with incomplete context. Cloud spend drifts upward without a clear owner. Teams respond by stacking more controls and more prompt variants. Progress slows.
Scale becomes manageable when GenAI is treated as a service with explicit constraints and measurable outcomes. It’s best to rely on a set of production disciplines to get there.
UST
Define the production contract
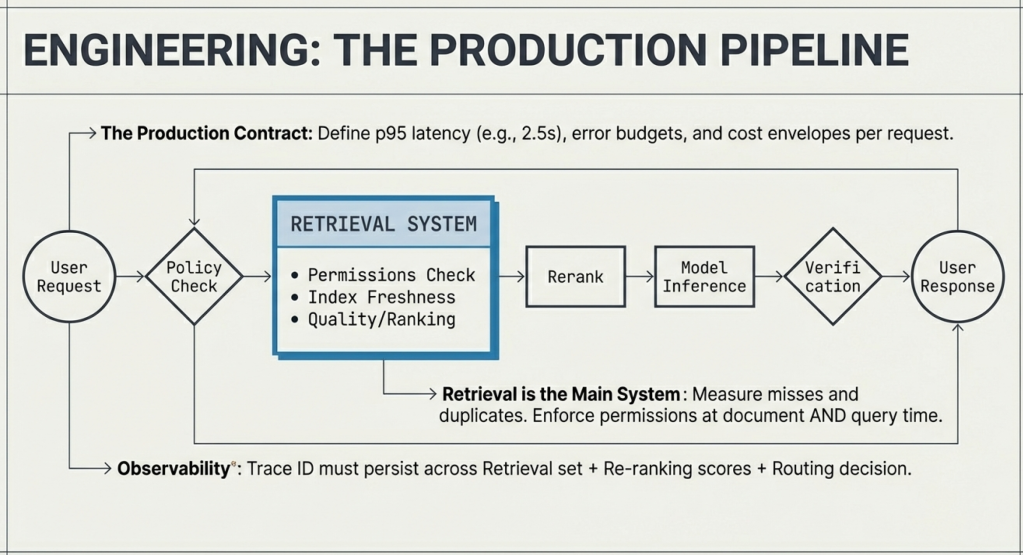
Write the contract for the experience you plan to operate. Put numbers on it. Include p95 latency, availability, error budget, and expected behavior under load. Add a cost envelope per request. Capture policy requirements for data access, citation, and tool use.
This step changes design choices quickly. A team with a 2.5-second p95 target makes different retrieval and routing choices than a team that can tolerate 10 seconds. A team with a three-cent per answer budget makes different model tier choices than a team with a fifty-cent budget.
Treat retrieval as the main system
Most enterprise assistants rely on retrieval-augmented generation. Retrieval drives answer quality. Retrieval also drives unit economics through context size, re-ranking, and repeat work. I spend more time on retrieval quality than on prompt wording.
A production retrieval layer has four properties.
- It enforces permissions at document time and at query time. Users should only see sources they can access, and the model should only read sources the user can access.
- It supports freshness and life cycle. Policies get updated. Wikis change. Indexes need clear ownership, a refresh cadence, and a rollback path.
- It measures retrieval quality. Teams need visibility into misses, duplicates that crowd out diversity, and chunking choices that break meaning.
- It produces context the model can use. That includes concise passages, stable identifiers for citations, and metadata that supports tracing.
Build an evaluation harness early
Continuous evaluation keeps the system stable as it evolves. A practical harness starts small.
Create a representative set of queries based on real user logs. Include ambiguous questions, known failure cases, and requests that require refusal.
Attach expectations. Some questions have a clear ground truth. Others can be expressed as constraints such as required citations, prohibited claims, or required policy language.
Measure retrieval and generation separately. Track recall and precision for retrieval with a labeled set of relevant documents. And track answer quality with automated checks plus targeted human review on high-risk paths.
Run the suite on every material change. That includes prompt updates, retriever tweaks, new data sources, and model version updates.
Instrument the pipeline from end to end
Teams often log only the prompt and the response. Production debugging needs more structure. I want a trace per request that includes the retrieval set, re-ranking scores, model routing decision, tool calls, policy decisions, and final output. I want a stable request ID that ties into incident workflows.
Observability should include outcome signals. A thumbs-up metric helps. A downstream outcome metric helps more. In support settings, track ticket resolution time. In engineering settings, track review cycle time.
UST
Control unit economics with routing
Token costs become material at scale. Cost control works best when it sits in the request path.
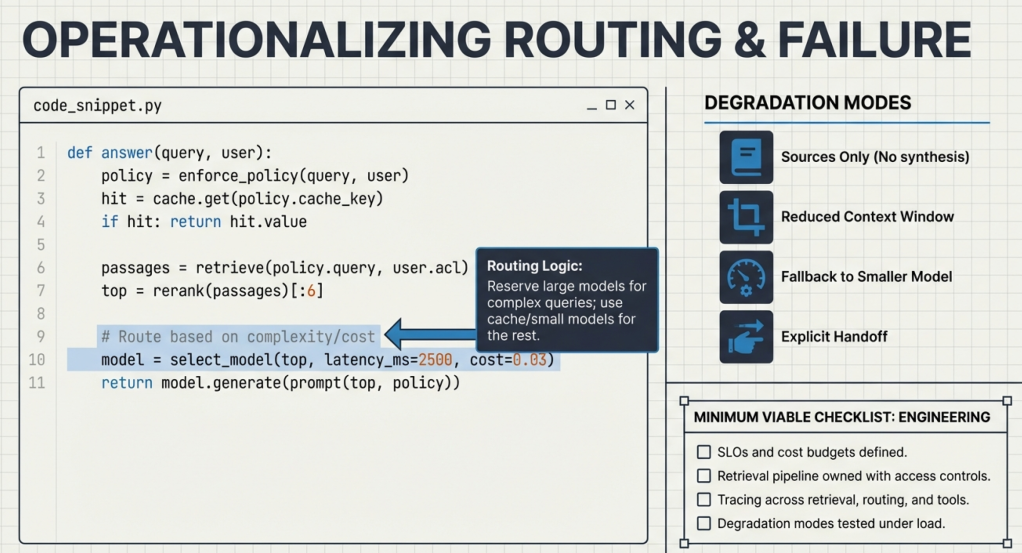
Use routing rules that start with cache and narrow context. Then choose the lightest model that meets the contract for the request. Reserve larger models for complex queries and tool-heavy flows. Keep a fallback that returns sources, asks for clarification, or hands off to a human queue.
A simplified routing sketch looks like this:
def answer(query, user):
policy = enforce_policy(query, user)
hit = cache.get(policy.cache_key)
if hit and hit.fresh:
return hit.value
passages = retrieve(policy.sanitized_query, user_acl=policy.acl)
top = rerank(passages)[:6]
model = select_model(top, latency_ms=2500, cost_cents=3)
draft = model.generate(build_prompt(top, policy))
checked = verify(draft, top, policy)
return finalize(checked, fallback="sources_only")
Each line should map to an owned component with metrics and an on-call plan.
Plan for graceful degradation
GenAI systems degrade in many ways. The vector store slows down. The model endpoint rate limits. A data source disappears. A tool returns partial results. Production readiness depends on predictable behavior during these moments.
Teams should design a small set of degradation modes and test them. Common modes include sources-only answers, reduced context, smaller models, and explicit handoff. The experience stays coherent when the system signals what it can do and logs why it changed behavior.
Minimum viable checklist
Use a short checklist before a broad rollout.
- SLOs and cost budgets reviewed by engineering, security, and the service owner.
- Retrieval pipeline owned, with access control, refresh cadence, and quality metrics.
- Evaluation suite running in CI, with regression thresholds and a human review path for high-risk flows.
- Tracing across retrieval, routing, and tool calls, with request IDs and redaction controls.
- Model routing and caching in place, with clear escalation rules.
- Degradation modes implemented and tested under load.
- Incident runbooks and rollback plans for prompts, retrievers, and model versions.
Invest for success
Enterprise GenAI becomes dependable when the surrounding system is engineered for operation. The work looks familiar to anyone who has run services at scale. It includes contracts, measurements, routing, and ownership. Teams that invest in these disciplines can change the system without guessing the impact.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.